들어가며
AI를 사용하다 보면 “토큰”이라는 단어를 자주 접하게 된다. Claude를 비롯한 대부분의 AI 서비스는 토큰 단위로 비용을 청구하는데, 많은 사용자가 이 개념을 정확히 이해하지 못해 예상치 못한 비용이 발생하기도 한다.
이번 차시에서는 Claude를 효율적으로 사용하기 위해 반드시 알아야 할 토큰의 개념과 LLM의 작동 원리를 살펴본다.
LLM(대규모 언어 모델) 이해
LLM이란 무엇인가
LLM(Large Language Model)은 수십억에서 수천억 개의 파라미터로 학습된 언어 모델이다. Claude, GPT, Gemini 등이 모두 LLM에 해당한다.
핵심 특징:
- 방대한 텍스트 데이터로 사전 학습
- 패턴 인식과 확률 기반으로 텍스트 생성
- 문맥(context)을 이해하고 응답 생성
작동 원리
LLM은 다음과 같은 방식으로 작동한다:
- 입력 처리: 사용자가 입력한 텍스트를 토큰으로 분해
- 패턴 인식: 학습된 데이터에서 유사한 패턴 탐색
- 확률 계산: 다음에 올 가장 적합한 토큰을 확률적으로 예측
- 텍스트 생성: 높은 확률의 토큰을 순차적으로 선택하여 응답 생성
예를 들어, “파이썬으로 피보나치 수열을”이라는 입력을 받으면, LLM은 학습 데이터에서 유사한 패턴을 찾아 “작성하는 방법은 다음과 같다:“라고 이어나갈 가능성이 높다.
LLM의 한계
LLM을 사용할 때 다음과 같은 한계를 이해해야 한다:
1. 지식 컷오프 날짜
Claude의 지식은 2025년 1월까지의 데이터로 학습되어 있다. 그 이후의 사건이나 정보는 알 수 없다. (글 작성 시점 기준)
# Claude에게 2025년 2월 이후 사건을 물으면
# "제 지식은 2025년 1월까지입니다"라는 답변을 받게 된다2. 수학적 정확성 제한
LLM은 패턴 기반이므로 복잡한 계산에서 실수할 수 있다.
# 간단한 계산은 정확하지만
2 + 2 = 4 # ✓
# 복잡한 수식은 오류 가능
# 예: 17자리 숫자의 소인수분해3. 환각(Hallucination)
LLM은 때때로 사실이 아닌 내용을 그럴듯하게 생성할 수 있다.
# 존재하지 않는 라이브러리나 함수를 제안할 수 있음
import fictional_library # 이런 라이브러리는 없음
# 항상 공식 문서로 검증 필요토큰의 개념과 계산
토큰이란
토큰(Token)은 AI가 텍스트를 처리하는 기본 단위다. 단어(word)와 비슷하지만 완전히 동일하지는 않다.
토큰화 방식:
- 영어: 단어나 서브워드 단위
- 한국어: 음절이나 형태소 단위
- 특수문자: 개별적으로 처리
토큰 계산 예시
영어 문장:
"Hello, world!" = 4 토큰
- "Hello" → 1 토큰
- "," → 1 토큰
- " world" → 1 토큰
- "!" → 1 토큰한국어 문장:
"안녕하세요" = 3-5 토큰
- 한국어는 영어 대비 1.5-2배 많은 토큰 사용
- 음절별 토큰화로 인한 특성코드:
def fibonacci(n):
if n <= 1:
return n
return fibonacci(n-1) + fibonacci(n-2)위 코드는 약 40-50 토큰으로 계산된다:
- 키워드(
def,if,return) → 각 1 토큰 - 변수명(
fibonacci,n) → 각 1-2 토큰 - 연산자(
<=,+,-) → 각 1 토큰 - 괄호와 공백 → 각 1 토큰
토큰 계산기 활용
Claude 토큰 계산기:
- URL: https://platform.claude.com/docs/en/build-with-claude/token-counting
- 실시간으로 토큰 수 확인 가능
- 다양한 언어 지원
사용 예시:
import anthropic
client = anthropic.Anthropic()
# 토큰 수 미리 계산
count = client.messages.count_tokens(
model="claude-sonnet-4-5-20250929",
messages=[
{"role": "user", "content": "Hello, Claude!"}
]
)
print(f"입력 토큰: {count.input_tokens}")
# 출력: 입력 토큰: 5토큰이 중요한 이유
토큰은 다음 두 가지 측면에서 중요하다:
1. 비용 계산
Claude API는 토큰 단위로 과금된다:
- Sonnet 4.5: 입력 $3/MTok, 출력 $15/MTok
- 1,000 토큰 사용 시 약 $0.003-$0.015
2. 컨텍스트 제한
각 모델은 한 번에 처리할 수 있는 토큰 수가 제한되어 있다:
- 기본: 200,000 토큰
- 베타: 1,000,000 토큰
입력 토큰 vs 출력 토큰
입력 토큰 (Input Tokens)
사용자가 Claude에게 제공하는 모든 텍스트다:
# 입력 토큰 구성
입력 = 시스템 프롬프트 + 사용자 메시지 + 대화 기록예시:
client.messages.create(
model="claude-sonnet-4-5-20250929",
system="You are a helpful assistant.", # 입력 토큰
messages=[
{"role": "user", "content": "Python으로 피보나치 함수 작성"} # 입력 토큰
]
)출력 토큰 (Output Tokens)
Claude가 생성하는 응답 텍스트다:
# Claude의 응답이 출력 토큰
response.content[0].text # 이 텍스트의 토큰 수대화에서의 토큰 흐름
대화를 이어갈 때, 이전 메시지의 출력 토큰이 다음 질문의 입력 토큰에 포함된다는 점이 중요하다.
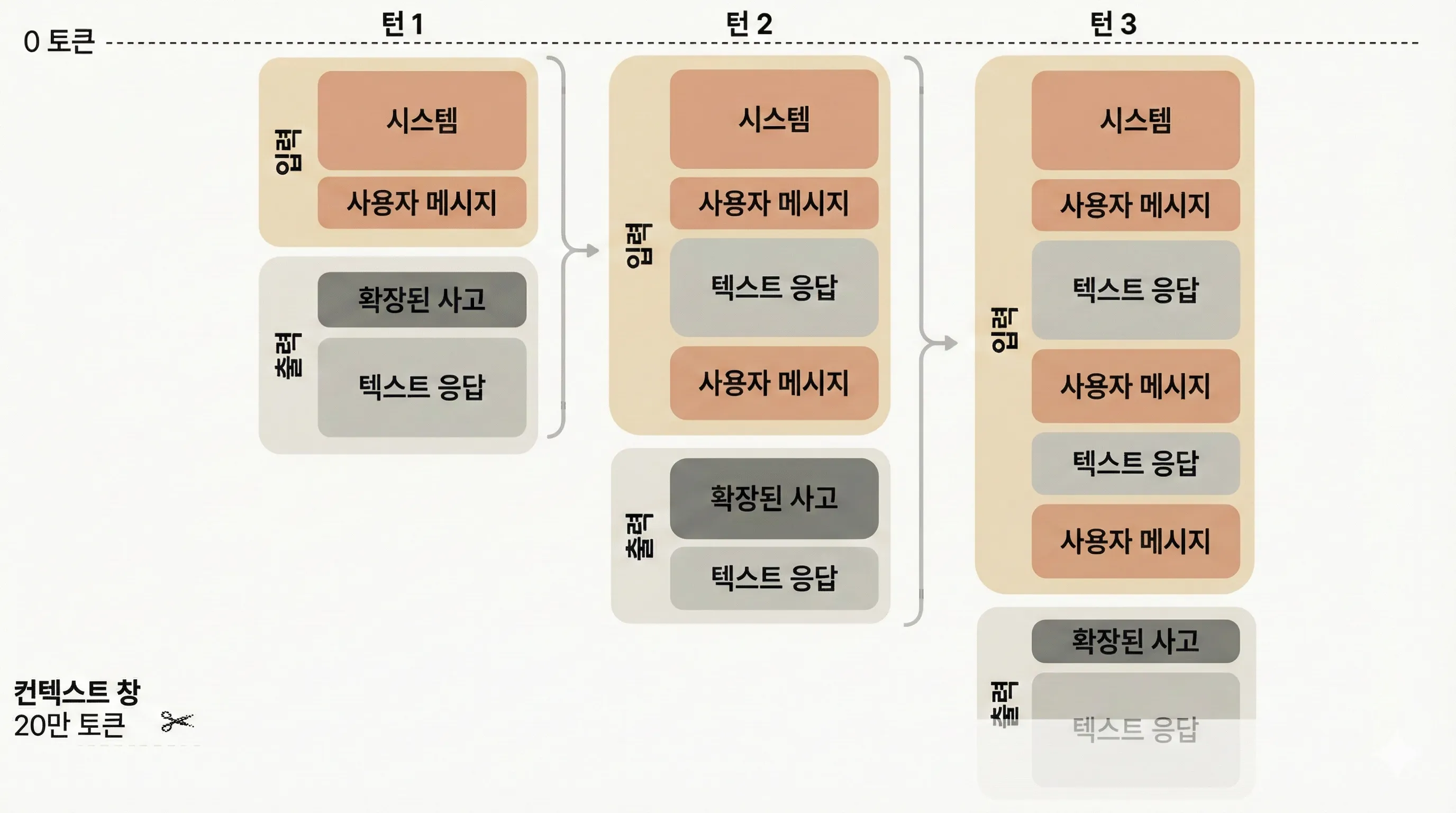
토큰 누적 예시:
# 첫 번째 요청
response1 = client.messages.create(
model="claude-sonnet-4-5-20250929",
messages=[
{"role": "user", "content": "Python이란?"} # 입력: 5 토큰
]
)
# Claude 응답: 200 토큰 (출력)
# 두 번째 요청 (대화 이어가기)
response2 = client.messages.create(
model="claude-sonnet-4-5-20250929",
messages=[
{"role": "user", "content": "Python이란?"}, # 첫 번째 질문
{"role": "assistant", "content": response1.content[0].text}, # 첫 번째 답변 (200 토큰)
{"role": "user", "content": "장점은?"} # 두 번째 질문 (5 토큰)
]
)
# 입력 토큰 = 5 + 200 + 5 = 210 토큰
# 출력 토큰 = 150 토큰 (새 응답)비용 계산:
# 첫 번째 요청
비용1 = (5 × $3 / 1,000,000) + (200 × $15 / 1,000,000)
= $0.000015 + $0.003
= $0.003015
# 두 번째 요청
비용2 = (210 × $3 / 1,000,000) + (150 × $15 / 1,000,000)
= $0.00063 + $0.00225
= $0.00288
# 총 비용 = $0.003015 + $0.00288 = $0.005895이처럼 대화가 길어질수록 입력 토큰이 누적되어 비용이 증가한다. 따라서 긴 대화 세션에서는 다음과 같은 전략이 필요하다:
- 새 대화 시작: 이전 컨텍스트가 필요 없으면 새 대화로 시작
- 요약 활용: 긴 대화 기록을 요약하여 토큰 절약
- 필요한 메시지만 유지: 전체 대화 기록 대신 최근 N개만 포함
비용 차이
핵심: 출력 토큰이 입력 토큰보다 5배 비쌉니다.
| 모델 | 입력 (MTok) | 출력 (MTok) | 비율 |
|---|---|---|---|
| Opus 4.6 | $5 | $25 | 1:5 |
| Sonnet 4.5 | $3 | $15 | 1:5 |
| Haiku 4.5 | $1 | $5 | 1:5 |
비용 계산 예시:
# 시나리오: 코드 리뷰 요청
입력: 2,000 토큰 (코드 + 요청사항)
출력: 1,000 토큰 (리뷰 결과)
모델: Sonnet 4.5
비용 = (2,000 × $3 / 1,000,000) + (1,000 × $15 / 1,000,000)
= $0.006 + $0.015
= $0.021 (약 28원)출력 토큰 제어
비용 절감을 위해 출력 토큰을 제한할 수 있다:
response = client.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=500, # 최대 500 토큰까지만 생성
messages=[{"role": "user", "content": "간단히 요약해줘"}]
)주의사항:
max_tokens를 너무 작게 설정하면 응답이 잘릴 수 있음- 일반적으로 1024-4096 사이 값 권장
- 긴 코드 생성 시 더 큰 값 필요
실전 사용량 분석
사용량 확인 코드
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=1024,
messages=[
{"role": "user", "content": "Python으로 간단한 웹 서버 작성"}
]
)
# 사용량 출력
print(f"입력 토큰: {response.usage.input_tokens}")
print(f"출력 토큰: {response.usage.output_tokens}")
# 비용 계산
input_cost = response.usage.input_tokens * 3 / 1_000_000
output_cost = response.usage.output_tokens * 15 / 1_000_000
total_cost = input_cost + output_cost
print(f"입력 비용: ${input_cost:.6f}")
print(f"출력 비용: ${output_cost:.6f}")
print(f"총 비용: ${total_cost:.6f}")출력 예시:
입력 토큰: 15
출력 토큰: 450
입력 비용: $0.000045
출력 비용: $0.006750
총 비용: $0.006795월간 비용 추정
개인 개발자 패턴:
일일 사용:
- 입력: 10,000 토큰 (질문, 코드 제공)
- 출력: 5,000 토큰 (답변, 생성 코드)
- 모델: Sonnet 4.5
일일 비용 = (10,000 × $3 / 1,000,000) + (5,000 × $15 / 1,000,000)
= $0.03 + $0.075
= $0.105
월간 비용 = $0.105 × 30일 = $3.15소규모 팀 패턴:
일일 사용 (팀 전체):
- 입력: 100,000 토큰
- 출력: 50,000 토큰
- 모델: Sonnet 4.5
일일 비용 = $0.30 + $0.75 = $1.05
월간 비용 = $31.50비용 최적화 전략
1. 적절한 모델 선택
# 간단한 질문은 Haiku 사용
simple_task = client.messages.create(
model="claude-haiku-4-5-20250929", # 가장 저렴
max_tokens=200,
messages=[{"role": "user", "content": "Hello"}]
)
# 복잡한 코딩은 Sonnet 사용
complex_task = client.messages.create(
model="claude-sonnet-4-5-20250929", # 균형잡힌 선택
max_tokens=2000,
messages=[{"role": "user", "content": "복잡한 알고리즘 구현"}]
)
# 최고 난이도는 Opus 사용
expert_task = client.messages.create(
model="claude-opus-4-6-20250629", # 최고 성능
max_tokens=4000,
messages=[{"role": "user", "content": "대규모 리팩토링 계획"}]
)2. 프롬프트 최적화
비효율적인 프롬프트:
prompt = """
다음 코드를 검토해주세요.
모든 부분을 자세하고 상세하게 분석해주시고,
가능한 모든 개선사항을 제안해주시며,
각 함수의 시간복잡도와 공간복잡도를 계산해주시고,
...
"""
# 불필요하게 긴 지시사항 → 입력 토큰 낭비효율적인 프롬프트:
prompt = """
코드 리뷰:
1. 버그 확인
2. 성능 개선 제안
3. 베스트 프랙티스 적용
[코드]
"""
# 간결하고 명확 → 입력 토큰 절약3. max_tokens 적절히 설정
# 짧은 답변 기대
response = client.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=200, # 간단한 답변용
messages=[{"role": "user", "content": "이 함수의 용도는?"}]
)
# 긴 코드 생성 기대
response = client.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=4096, # 긴 응답용
messages=[{"role": "user", "content": "전체 API 서버 작성"}]
)4. 대화 기록 관리
# 매번 새로운 대화로 시작 (불필요한 컨텍스트 제거)
for task in tasks:
response = client.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=1024,
messages=[ # 이전 대화 포함하지 않음
{"role": "user", "content": task}
]
)한국어와 영어의 토큰 차이
토큰 사용량 비교
동일한 의미의 텍스트도 언어에 따라 토큰 수가 다르다:
영어:
"Please write a Python function to calculate Fibonacci numbers."
→ 약 12 토큰한국어:
"파이썬으로 피보나치 수를 계산하는 함수를 작성해주세요."
→ 약 20-24 토큰 (영어 대비 1.7-2배)비용 영향
# 영어 사용 시
영어 입력: 1,000 토큰
영어 출력: 2,000 토큰
비용 = $0.003 + $0.030 = $0.033
# 한국어 사용 시
한국어 입력: 1,700 토큰 (1.7배)
한국어 출력: 3,400 토큰 (1.7배)
비용 = $0.0051 + $0.051 = $0.0561 (약 1.7배)최적화 팁
# 프롬프트는 영어, 코드는 그대로
prompt = """
Analyze this code and suggest improvements:
[Python 코드]
"""
# 영어 프롬프트 + 코드 → 토큰 절약
# 응답도 영어로 받기
prompt = """
Answer in English:
[질문]
"""정리
핵심 요점
- LLM은 패턴 기반: 확률적으로 텍스트를 생성하므로 한계가 있다
- 토큰은 비용의 기준: 입력과 출력 토큰을 모두 고려해야 한다
- 출력 토큰이 5배 비쌈: 응답 길이 제어가 중요하다
- 한국어는 토큰을 더 많이 사용: 영어 대비 1.5-2배
- 적절한 모델 선택: 작업 난이도에 맞는 모델 사용
체크리스트
- LLM의 작동 원리 이해
- 토큰의 개념 파악
- 입력 토큰과 출력 토큰의 차이 숙지
- 토큰 계산기 사용법 습득
- 비용 계산 방법 이해
- 프롬프트 최적화 전략 학습
다음 단계
다음 차시에서는 Claude의 세 가지 모델(Opus, Sonnet, Haiku)을 상세히 비교하고, 각 모델의 특징과 최적 사용 사례를 알아본다.